I am a freelance DevOps and Test Automation Engineer specializing in microservice applications, performance optimization, and cloud-based test environments (AWS, Azure, and GCP).
Feel free to contact me for questions and requests:
info <at> martingrambow.com
I am a freelance DevOps and Test Automation Engineer specializing in microservice applications, performance optimization, and cloud-based test environments (AWS, Azure, and GCP).
Feel free to contact me for questions and requests:
info <at> martingrambow.com

Martin Grambow
Research Associate
Public Software Projects
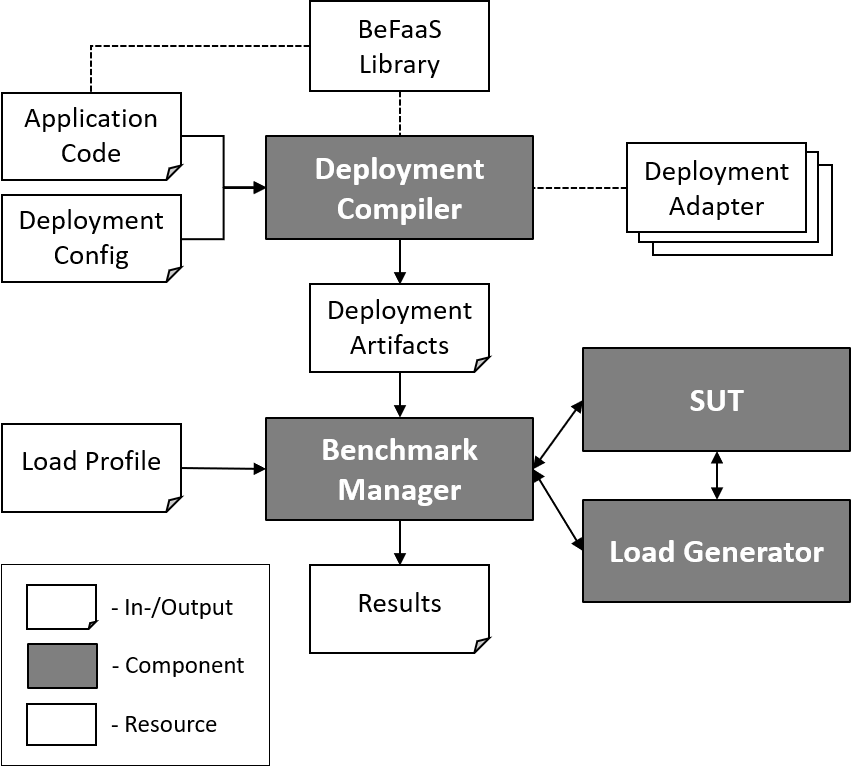
BeFaaS
2020
BeFaaS is an extensible open-source benchmarking framework for FaaS environments which comes with two built-in benchmark suites and respective load profiles: An E-commererce application (web shop) and an IoT application (smart traffic light). BeFaas is the first benchmarking framework which enables the federated benchmark of FaaS providers: Users can split their application and define which function(s) should run on which provider. Currently, BeFaaS supports six FaaS providers on which (parts of) the test suite applications can be deployed and evaluated: AWS Lambda, Google Cloud Functions, Azure Functions, TinyFaaS, OpenFaaS, and OpenWhisk.
show more
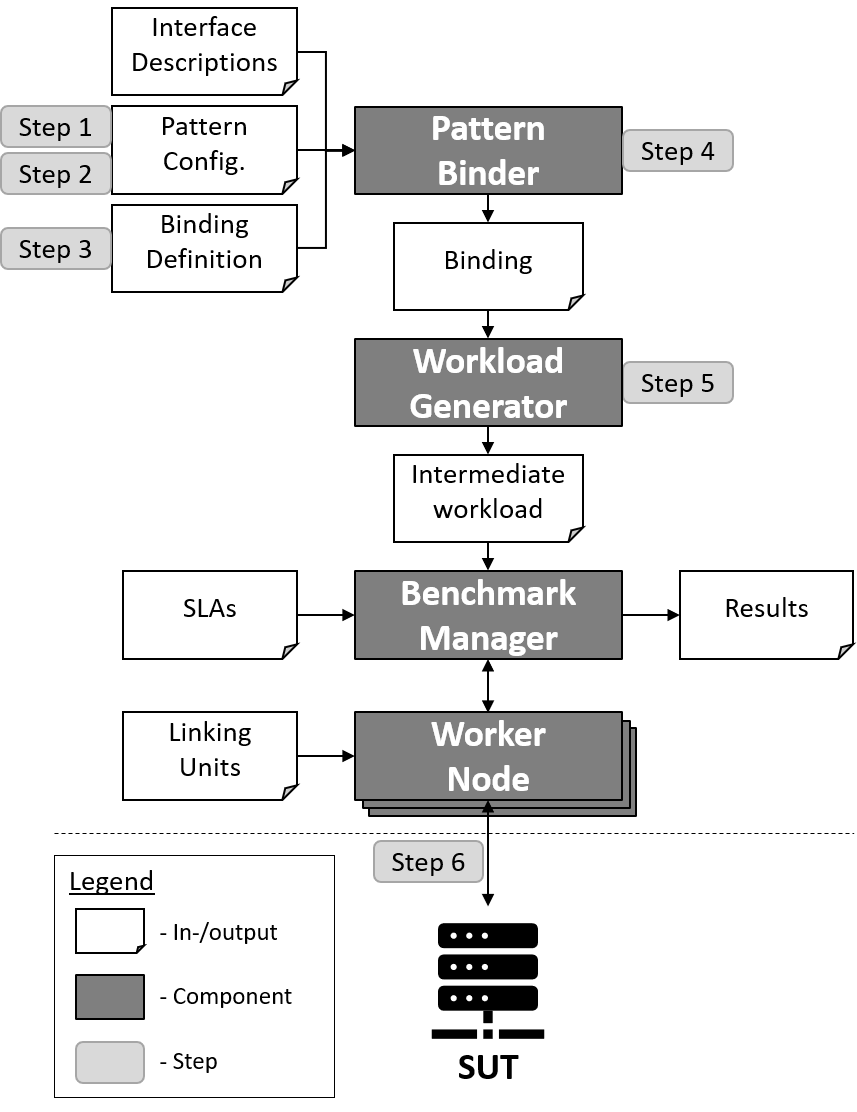
OpenISBT
2020
OpenISBT is an Intelligent Service Benchmark Tool to benchmark microservice-based applications based on their OpenAPI 3.0 interface description files. It implements a pattern-based approach to reduce the efforts for defining microservice benchmarks, while still allowing to measure qualities of complex interactions. It assumes that microservices expose a REST API, described in a machine-understandable way, and allows developers to model interaction patterns from abstract operations that can be mapped to that API. Possible data dependencies between operations are resolved at runtime.
show more
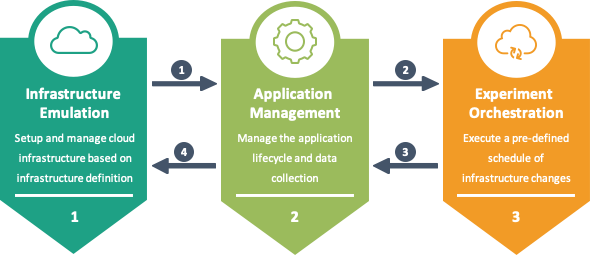
MockFog2
2020
Fog computing is an emerging computing paradigm that uses processing and storage capabilities located at the edge, in the cloud, and possibly in between. Testing fog applications, however, is hard since runtime infrastructures will typically be in use or may not exist, yet. MockFog is a tool that can be used to emulate such infrastructures in the cloud. Developers can freely design emulated fog infrastructures and configure their performance characteristics. With MockFog 2.0, developers can also manage application components and do experiment orchestration.
show more
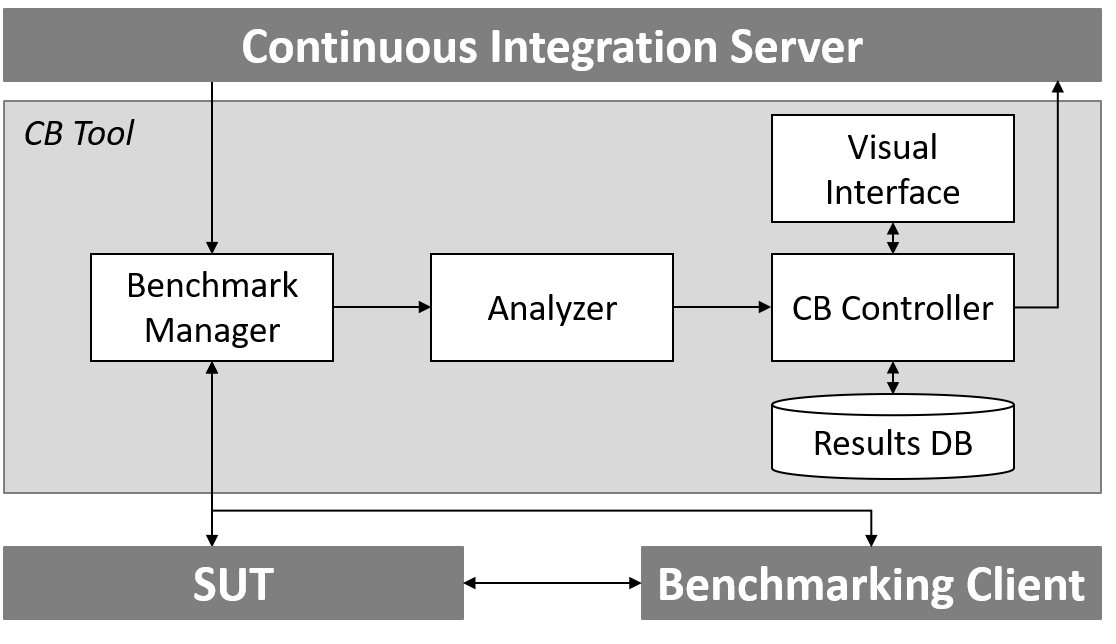
Continuous Benchmarking Plug-In
2019
Continuous integration and deployment are established paradigms in modern software engineering. Both intend to ensure the quality of software products and to automate the testing and release process. Today’s state of the art, however, focuses on functional tests or small microbenchmarks such as single method performance while the overall quality of service(QoS) is ignored. We want to extend these pipelines with an additional application benchmark step which ensures QoS requirements and prevents performance regressions. This Plugin analyzes results and detects the violation of fixed performance metrics (e.g., defined in SLAs), sudden significant performance fluctuations, and long lasting regression trends.
show more
Select Publications

Efficiently Detecting Performance Changes in FaaS Application Releases
M. Grambow, T. Dockenfuß, T. Schirmer, N. Japke, D. Bermbach
Proc. of International Workshop on Serverless Computing (WoSC '23) - ACM
2023
The source code of Function as a Service (FaaS) applications is constantly being refined. To detect if a source code change introduces a significant performance regression, the traditional benchmarking approach evaluates both the old and new function version separately using numerous artificial requests. In this paper, we describe a wrapper approach that enables the Randomized Multiple Interleaved Trials (RMIT) benchmark execution methodology in FaaS environments and use bootstrapping percentile intervals to derive more accurate confidence intervals of detected performance changes. We evaluate our approach using two public FaaS providers, an artificial performance issue, and several benchmark configuration parameters. We conclude that RMIT can shrink the width of confidence intervals in the results from 10.65% using the traditional approach to 0.37% using RMIT and thus enables a more fine-grained performance change detection.
show more

Using Microbenchmark Suites to Detect Application Performance Changes
M. Grambow, D. Kovalev, C. Laaber, P. Leitner, D. Bermbach
Transactions on Cloud Computing - IEEE
2022
Software performance changes are costly and often hard to detect pre-release. Similar to software testing frameworks, either application benchmarks or microbenchmarks can be integrated into quality assurance pipelines to detect performance changes before releasing a new application version. Unfortunately, extensive benchmarking studies usually take several hours which is problematic when examining dozens of daily code changes in detail; hence, trade-offs have to be made. Optimized microbenchmark suites, which only include a small subset of the full suite, are a potential solution for this problem, given that they still reliably detect the majority of the application performance changes such as an increased request latency. It is, however, unclear whether microbenchmarks and application benchmarks detect the same performance problems and one can be a proxy for the other. In this paper, we explore whether microbenchmark suites can detect the same application performance changes as an application benchmark. For this, we run extensive benchmark experiments with both the complete and the optimized microbenchmark suites of two time-series database systems, i.e., InfluxDB and VictoriaMetrics , and compare their results to the results of corresponding application benchmarks. We do this for 70 and 110 commits, respectively. Our results show that it is not trivial to detect application performance changes using an optimized microbenchmark suite. The detection (i) is only possible if the optimized microbenchmark suite covers all application-relevant code sections, (ii) is prone to false alarms, and (iii) cannot precisely quantify the impact on application performance. For certain software projects, an optimized microbenchmark suite can, thus, provide fast performance feedback to developers (e.g., as part of a local build process), help estimating the impact of code changes on application performance, and support a detailed analysis while a daily application benchmark detects major performance problems. Thus, although a regular application benchmark cannot be substituted for both studied systems, our results motivate further studies to validate and optimize microbenchmark suites.
show more
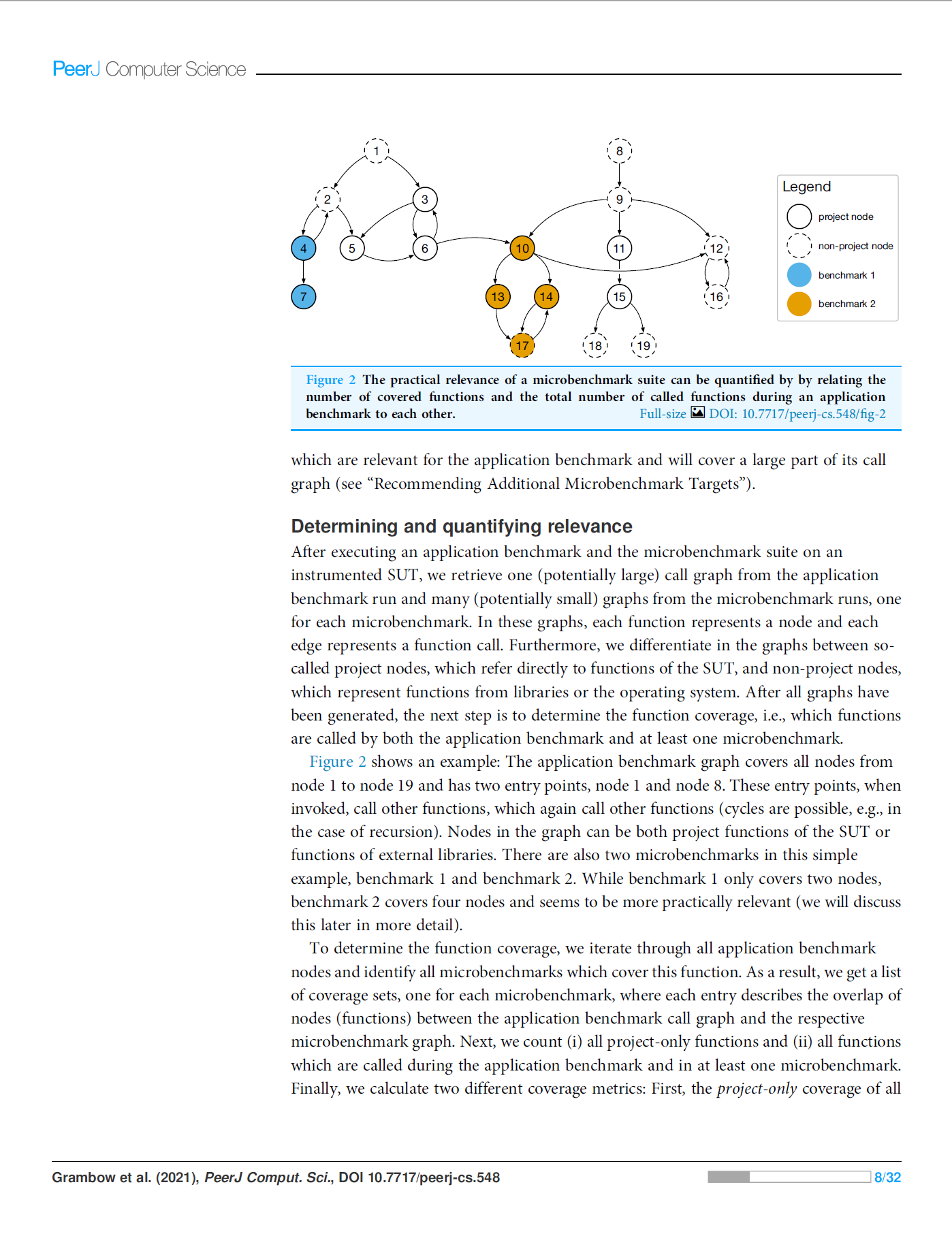
Using Application Benchmark Call Graphs to Quantify and Improve the Practical Relevance of Microbenchmark Suites
M. Grambow, C. Laaber, P. Leitner, D. Bermbach
PeerJ Computer Science - PeerJ
2021
Performance problems in applications should ideally be detected as soon as they occur, i.e., directly when the causing code modification is added to the code repository. To this end, complex and cost-intensive application benchmarks or lightweight but less relevant microbenchmarks can be added to existing build pipelines to ensure performance goals. In this paper, we show how the practical relevance of microbenchmark suites can be improved and verified based on the application flow during an application benchmark run. We propose an approach to determine the overlap of common function calls between application and microbenchmarks, describe a method which identifies redundant microbenchmarks, and present a recommendation algorithm which reveals relevant functions that are not covered by microbenchmarks yet. A microbenchmark suite optimized in this way can easily test all functions determined to be relevant by application benchmarks after every code change, thus, significantly reducing the risk of undetected performance problems. Our evaluation using two time series databases shows that, depending on the specific application scenario, application benchmarks cover different functions of the system under test. Their respective microbenchmark suites cover between 35.62% and 66.29% of the functions called during the application benchmark, offering substantial room for improvement. Through two use cases — removing redundancies in the microbenchmark suite and recommendation of yet uncovered functions — we decrease the total number of microbenchmarks and increase the practical relevance of both suites. Removing redundancies can significantly reduce the number of microbenchmarks (and thus the execution time as well) to ~10% and ~23% of the original microbenchmark suites, whereas recommendation identifies up to 26 and 14 newly, uncovered functions to benchmark to improve the relevance. By utilizing the differences and synergies of application benchmarks and microbenchmarks, our approach potentially enables effective software performance assurance with performance tests of multiple granularities.
show more

Benchmarking the Performance of Microservice Applications
M. Grambow, E. Wittern, D. Bermbach
ACM SIGAPP Applied Computing Review (ACR) - ACM
2020
Application performance is crucial for end user satisfaction. It has therefore been proposed to benchmark new software releases as part of the build process. While this can easily be done for system classes which come with a standard interface, e.g., database or messaging systems, benchmarking microservice applications is hard because each application requires its own custom benchmark and benchmark implementation due to interface heterogeneity. Furthermore, even minor interface changes will easily break an existing benchmark implementation. In previous work, we proposed a benchmarking approach for single microservices: Assuming a REST-based microservice interface, developers describe the benchmark workload based on abstract interaction patterns. At runtime, our approach uses an interface description such as the OpenAPI specification to automatically resolve and bind the workload patterns to the concrete endpoint before executing the benchmark and collecting results. In this extended paper, we enhance our approach with the capabilities necessary for benchmarking entire microservice applications, especially the ability to resolve complex data dependencies across microservice endpoints. We evaluate our approach through our proof-of-concept prototype OpenISBT and demonstrate that it can be used to benchmark an open source microservice application with little manual effort.
show more

Continuous Benchmarking: Using System Benchmarking in Build Pipelines
M. Grambow, F. Lehmann, D. Bermbach
Proc. of IEEE International Conference on Cloud Engineering (IC2E '19) - IEEE
2019
Continuous integration and deployment are established paradigms in modern software engineering. Both intend to ensure the quality of software products and to automate the testing and release process. Today's state of the art, however, focuses on functional tests or small microbenchmarks such as single method performance while the overall quality of service (QoS) is ignored. In this paper, we propose to add a dedicated benchmarking step into the testing and release process which can be used to ensure that QoS goals are met and that new system releases are at least as "good" as the previous ones. For this purpose, we present a research prototype which automatically deploys the system release, runs one or more benchmarks, collects and analyzes results, and decides whether the release fulfills predefined QoS goals. We evaluate our approach by replaying two years of Apache Cassandra's commit history.
show more

MockFog: Emulating Fog Computing Infrastructure in the Cloud
J. Hasenburg, M. Grambow, E. Grünewald, S. Huk, D. Bermbach
Proc. of IEEE International Conference on Fog Computing (ICFC '19) - IEEE
2019
Fog computing is an emerging computing paradigm that uses processing and storage capabilities located at the edge, in the cloud, and possibly in between. Testing fog applications, however, is hard since runtime infrastructures will typically be in use or may not exist, yet. In this paper, we propose an approach that emulates such infrastructures in the cloud. Developers can freely design emulated fog infrastructures, configure their performance characteristics, and inject failures at runtime to evaluate their application in various deployments and failure scenarios. We also present our proof-of-concept implementation MockFog and show that application performance is comparable when running on MockFog or a small fog infrastructure testbed.
show more

Public Video Surveillance: Using the Fog to Increase Privacy
M. Grambow, J. Hasenburg, D. Bermbach
Proc. of the 5th Workshop on Middleware and Applications for the Internet of Things (M4IoT '18) - ACM
2018
In public video surveillance, there is an inherent conflict between public safety goals and privacy needs of citizens. Generally, societies tend to decide on middleground solutions that sacrifice neither safety nor privacy goals completely. In this paper, we propose an alternative to existing approaches that rely on cloud-based video analysis. Our approach leverages the inherent geo-distribution of fog computing to preserve privacy of citizens while still supporting camera-based digital manhunts of law enforcement agencies.
show more
Experience
Freelance DevOps and Test Automation Engineer
Self-Employed
2024 - now
Currently, I offer tailored automation and optimization concepts for web and microservice applications in cloud environments. My focus is on CI/CD pipelines, test automation, and efficient deployment processes.

Research Associate
Technische Universität Berlin
2018 - 24
Member of the Scalable Software Systems research group and supervisor of the courses "Introduction to Programming in Java", "Fog Computing", and "(Advanced) Distributed Systems Prototyping".

Software Developer
LucaNet AG
2017 - 18
Design, planning, and implementation of software for financial consolidation of companies, analysis of controlling data, and reporting.
Teaching Assistant
Technische Universität Berlin
2013 - 17
Tutorials for the courses "Technical Foundations of Computer Science" ('13 - '14), "Business Processes" ('14), "Application Systems" ('15), and "Theoretical Foundations of Computer Science" ('15 - '17)

Software Tester
Beta Systems Software AG
2012 - 13
Test automation using Jenkins and Selenium WebDriver.
Education
Informatics (Ph.D.)
Technische Universität Berlin
2018 - 24
Focus on benchmarking microservices, continuous integration/deployment pipelines, and fog computing.
Information Systems Management (M.Sc.)
Technische Universität Berlin
2015 - 17
Advanced courses in distributed systems, software security, quality assurance, standardization, and controlling.
Information Systems Management (B.Sc.)
Technische Universität Berlin
2012 - 15
Fundamentals of mathematics, computer science, and business administration. Personal focus on project management, business processes, and software development.

Computer Science Expert (Subject Area: Software Development)
OSZ IMT - Berlin College of Further Education for Information Technology and Medical Equipment Technology
2009 - 12
Certified by Chamber of Industry and Commerce.